
宏定义与条件编译
宏定义:
- 定义形式:
用一个指定的标志符来代表一个字符串,其定义为:
1 |
- 功能用途:
- 可以减少程序中重复性输入某些重用字符串的工作量。
- 一改全改
条件编译
- 定义:
一般情况下,源程序中所有的行都要参加编译,但有时候需要对程序中某一部分在满足一定的情况下才进行编译,也就是对部分程序限定编译条件;另外,我们希望当满足某一条件时对一组程序进行编译,当满足另外一种情况时则编译另外一组程序。
- 使用方法:
主要由两种形式,类似于判断语句,宏定义相当于编译的开关:
1 |
|
结构体与类的定义与区别
C结构体、C++结构体基本相同,C++类主要是方法的实现。
结构体是数据类型的集合
类是数据类型加方法的集合,基本如此,更注重方法。
malloc
- 在链表中插入新的结点时可能会用的到
- 头文件#include<malloc.h>
- 功能:分配长度为num_bytes字节的内存块
- 说明:如果分配成功则返回指向被分配内存的指针,否则返回空指针NULL。
- 当内存不再使用时,应使用free()函数将内存块释放
- malloc()函数其实就在内存中找一片指定大小的空间,然后将这个空间的首地址范围给一个指针变量,这里的指针变量可以是一个单独的指针,也可以是一个数组的首地址,这要看malloc()函数中参数size的具体内容。我们这里malloc分配的内存空间在逻辑上连续的,而在物理上可以连续也可以不连续。对于我们程序员来说,我们关注的是逻辑上的连续,因为操作系统会帮我们安排内存分配,所以我们使用起来就可以当做是连续的。
- 注意的地方:由于malloc函数返回的是void 类型。对于C++,如果你写成:p = malloc (sizeof(int));则程序无法通过编译,报错:“不能将void*赋值给int *类型变量”。所以必须通过(int *)来将强制转换。而对于C,没有这个要求,但为了使C程序更方便的移植到C++中来,建议养成强制转换的习惯
1
2
3
4
5int* p;
//分配128个(可根据实际需要替换该数值)整型存储单元,并将这128个连续的整型存储单元的首地址存储到指针变量p中
p = (int *) malloc (sizeof(int)*128);
//分配12个double型存储单元,并将首地址存储到指针变量pd中
double *pd=(double *) malloc (sizeof(double)*12);
1 |
|
typedef的用法
- typedef主要是用来自定义数据类型,可以对所有现存的数据类型进行个性化的重新定义,增加所对应类型变量的个性化程度与单一性,便于在众多变量中将某一大类具有相似关系的变量统一定义。
- 用在旧的C的代码中(具体多旧没有查),帮助struct。以前的代码中,声明struct新对象时,必须要带上struct,即形式为: struct 结构名 对象名,如:
1
2
3
4
5
6struct tagPOINT1
{
int x;
int y;
};
struct tagPOINT1 p1; - 可能现在在C++中没有那么明显,可以直接写 结构名 对象名,或许,在C++中,typedef的这种用途二不是很大,但是理解了它,对掌握以前的旧代码还是有帮助的,毕竟我们在项目中有可能会遇到较早些年代遗留下来的代码。
- 但在C中估计某人觉得经常多写一个struct太麻烦了,于是就发明了:
1
2
3
4
5
6
7typedef struct tagPOINT
{
int x;
int y;
}POINT;
POINT p1; // 这样就比原来的方式少写了一个struct,比较省事,尤其在大量使用的时候
z=x>y? x : y
其实,这是一个非常基本的知识点,但是有些时候突然见到会想不起来,翻译一下就相当于:
1 | if(x>y) |
也就是可以理解为result=条件 ? 结果1 : 结果2 里面的?号是格式要求。也可以理解为条件是否成立,条件成立为结果1,否则为结果2。
memset()函数与数组初始化函数
这个函数在socket中多用于清空数组.如:原型是memset(buffer, 0, sizeof(buffer))。简言之,就是用来将数组进行初始化的函数。
有时候我们并不一定需要动用vector来定义数组,而是可以通过直接定义数组,再结合实际需求通过memset函数来对数组进行初始化操作,这种应用在动态规划类型的题目中应用较多。
- 这个函数有三个参数,前两个为初始化数组对象及其初始化的值,最后一个通常使用sizeof()函数来写,也可以直接写具体大小n。
- 注意,如果是对指针变量所指向的内存单元进行清零初始化,那么一定要先对这个指针变量进行初始化,即一定要先让它指向某个有效的地址。而且用memset给指针变量如p所指向的内存单元进行初始化时,n 千万别写成 sizeof(p),这是新手经常会犯的错误。因为 p 是指针变量,不管 p 指向什么类型的变量,sizeof(p) 的值都是 4。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
int main()
{
int i; //循环变量
char str[10] = {1,2,3,4,5,6,7,8,9,0};
char *p = str;
memset(str, 0, sizeof(str)); //只能写sizeof(str), 不能写sizeof(p)
for (i=0; i<10; ++i)
{
printf("%d\x20", str[i]);
}
printf("\n");
//int直接来对数组进行定义
int m=str.size();
int n=str.size();
int dp[m][n];
int Initial_value;
memset(dp,Initial_value,sizeof(dp));
return 0;
}vector的使用
vector在C++的功能与数组类似,不过其优点在于其大小长度为动态的,在进行初始化定义的时候并不需要像数组那样去初始化其长度。同时,其特殊之处又决定了vector具体在使用时需要注意的细节:- 往其中加入新元素时需要用 数组名.push_back(加入的元素) 来实现,而不能直接访问为初始化或者未定义的下标。
- 同时也可以对其进行初始化n个元素。
1
2
3
4vector<int> nums;//定义动态数组nums
//nums.[0]=0 //不可以对未定义下标直接赋值
nums.psuh_back(1)//相当于数组中的nums[0]=1;
nums[0]=100; //可以修改已定义的下标getchar()和system(“puse”)函数
这两个可以用在VScode的最后面,用于终端窗口的保持,防止其弹出瞬间就突然消失。 - 有时,我们不希望终端窗口弹出,因为只需要在下面的终端栏中也可现实。关闭窗口的弹出可以修改.vscode文件下的lanunch.json,将下面的 “externalConsole” 初始设置为false即可。(可根据个人喜好更改)
1
"externalConsole": false,
枚举类型menu的用法
众所周知,C/C++语言可以使用#define和const创建符号常量,而使用enum工具不仅能够创建符号常量,还能定义新的数据类型,但是必须按照一定的规则进行,下面我们一起看下enum的使用方法
- (1)以下代码定义了这种新的数据类型 - 枚举型(1) 枚举型是一个集合,集合中的元素(枚举成员)是一些命名的整型常量,元素之间用逗号,隔开。
1
2
3
4enum DAY
{
MON=1, TUE, WED, THU, FRI, SAT, SUN
};
(2) DAY是一个标识符,可以看成这个集合的名字,是一个可选项,即是可有可无的项。
(3) 第一个枚举成员的默认值为整型的0,后续枚举成员的值在前一个成员上加1。
(4) 可以人为设定枚举成员的值,从而自定义某个范围内的整数。
(5) 枚举型是预处理指令#define的替代。
(6) 类型定义以分号;结束。
- (2)用typedef关键字将枚举类型定义成别名,并利用该别名进行变量声明后面就可以直接使用workday来定义枚举类型了,比如
1
2
3
4
5
6
7
8
9
10typedef enum workday
{
saturday,
sunday = 0,
monday,
tuesday,
wednesday,
thursday,
friday
} workday; //此处的workday为枚举型enum workday的别名具体使用参考示例(C语言):1
workday today, tomorrow; //变量today和tomorrow的类型为枚举型workday,也即enum workday
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
enum Season
{
spring, summer=100, fall=96, winter
};
typedef enum
{
Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday
}
Weekday;
void main()
{
/* Season */
printf("%d \n", spring); // 0
printf("%d, %c \n", summer, summer); // 100, d
printf("%d \n", fall+winter); // 193
Season mySeason=winter;
if(winter==mySeason)
printf("mySeason is winter \n"); // mySeason is winter
int x=100;
if(x==summer)
printf("x is equal to summer\n"); // x is equal to summer
printf("%d bytes\n", sizeof(spring)); // 4 bytes
/* Weekday */
printf("sizeof Weekday is: %d \n", sizeof(Weekday)); //sizeof Weekday is: 4
Weekday today = Saturday;
Weekday tomorrow;
if(today == Monday)
tomorrow = Tuesday;
else
tomorrow = (Weekday) (today + 1); //remember to convert from int to Weekday
}
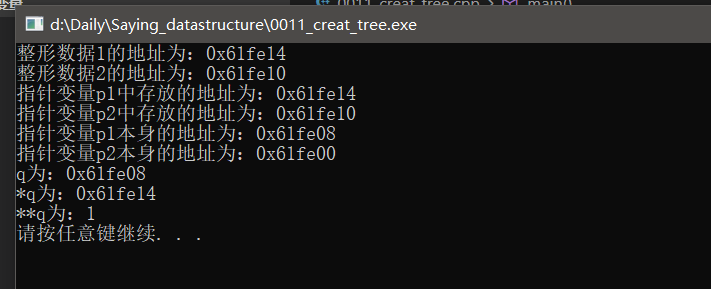
二重指针
所谓的二重指针,就是一种指向指针变量类型的指针。首先对于一个指针变量而言,它需要占用内存空间,即它本身是具有地址的,只不过对应内存空间中存放的是指针变量所指向变量的地址。
1 | int a=1; |
程序的输出为:
异或操作(^)
位运算是C++中比较基础的知识点,常见的位运算操作:
- 左移与右移 <<(左移),>>(右移),左右移动主要是参照箭头的朝向
- 与(&) 或(|) 取反(~) 异或(^)
关于C++中map和unordered_map的使用
map是一种以键值对的形式来存储元素的结构,并且也提供相应的成员函数来协助高效的插入,查询和删除键值对,除了map之外,还有一个名为unordered_map的结构,下面研究一下这两者的区别:
- 1、引用的头文件
1
2map :
unordered_map : - 2、存储结构
map是将元素存储在一个平衡二叉树中,因此元素是有序存储的
unordered_map是将元素存储在一个哈希表中,正如其名字一样,他并不是有序存储的
- 3、内存使用
因为需要额外的内存来存储哈希表,因此unordered_map比map更占用内存
- 4、优缺点分析及其适用处
map
map的存储形式就是以键值对形式存在的,map只要定义完成后,就可以像数组那样去访问键值对以及对键值对进行赋值操作。
map在使用时候需要在头文件中加入#include<map.h>,下面看一个简单的例程。
1 |
|
优点:
有序性,这是map结构最大的优点,其元素的有序性在很多 应用中都会简化很多的操作树,内部实现一个树使得map的很多操作在logn的时间复杂度下就可以实现,因此效率非常的高
缺点:
空间占用率高,因为map内部实现了树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点,使得每一个节点都占用大量的空间
适用处:
对于那些有顺序要求的问题,用map会更高效一些
unordered_map
优点:
因为内部实现了哈希表,因此其查找速度非常的快
缺点:
哈希表的建立比较耗费时间
适用处:
对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map
- 举例分析:(罗马数字与阿拉伯数字转换,巧用map):
Roman numerals are represented by seven different symbols: I, V, X, L, C, D and M.
Symbol Value
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
For example, two is written as II in Roman numeral, just two one’s added together. Twelve is written as, XII, which is simply X + II. The number twenty seven is written as XXVII, which is XX + V + II.
Roman numerals are usually written largest to smallest from left to right. However, the numeral for four is not IIII. Instead, the number four is written as IV. Because the one is before the five we subtract it making four. The same principle applies to the number nine, which is written as IX. There are six instances where subtraction is used:
I can be placed before V (5) and X (10) to make 4 and 9.
X can be placed before L (50) and C (100) to make 40 and 90.
C can be placed before D (500) and M (1000) to make 400 and 900.
Given a roman numeral, convert it to an integer. Input is guaranteed to be within the range from 1 to 3999.
Example 1:
Input: “III”
Output: 3
Example 2:
Input: “IV”
Output: 4
Example 3:
Input: “IX”
Output: 9
Example 4:
Input: “LVIII”
Output: 58
Explanation: L = 50, V= 5, III = 3.
Example 5:
Input: “MCMXCIV”
Output: 1994
Explanation: M = 1000, CM = 900, XC = 90 and IV = 4.
这道题我们就可以借助map来进行实现,具体代码实现如下:
1 | class Solution { |
sort()函数的用法
在进行程序书写过程中,有时候要对向量或者数组按照一定的顺序排列,当然可以通过排序算法进行排序,但是熟练到一定程度之后,我们可以通过直接使用sort()函数来对数组按照自己的需求意愿进行简单的排序。
- 关于sort()函数
sort()函数位于C++的标准库#include中,调用标准库里面的排序方法可以实现对数据的排序 - sort()函数的三个参数
void sort (RandomAccessIterator first, RandomAccessIterator last, Compare comp);
(1)第一个参数first:是要排序的数组的起始地址。
(2)第二个参数last:是结束的地址(最后一个数据的后一个数据的地址)
(3)第三个参数comp是排序的方法:可以是从升序也可是降序。如果第三个参数不写,则默认的排序方法是从小到大排序,**注意在leetcode,类中定义cmp函数时,如果cmp函数同为public属性,那么bool cmp一定要写为static bool cmp函数。具体原因:
写参数cmp时,是把函数名作为实参传递给了sort函数,而sort函数内部是用一个函数指针去调用这个cmp函数的(建议先看下 一文搞懂什么是 函数指针 ),我们知道class普通类成员函数cmp需要通过对象名.cmp()来调用,而sort()函数早就定义好了,那个时候哪知道你定义的是什么对象,所以内部是直接cmp()的,那你不加static时,去让sort()直接用cmp()当然会报错
static静态成员函数不用加对象名,就能直接访问函数(这也是静态成员函数的一大优点)所以加了static就不会报错
- 实例
(1)默认情况下:(2)声名情况下1
2
3
4
5
6
7
8
9
10
11
12
using namespace std;
main()
{
//sort函数第三个参数采用默认从小到大
int a[]={45,12,34,77,90,11,2,4,5,55};
//没有对cmp进行定义
sort(a,a+10);
for(int i=0;i<10;i++)
cout<<a[i]<<" ";
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
using namespace std;
bool cmp(int a,int b);
main(){
//sort函数第三个参数自己定义,实现从大到小
int a[]={45,12,34,77,90,11,2,4,5,55};
sort(a,a+10,cmp);
for(int i=0;i<10;i++)
cout<<a[i]<<" ";
}
//自定义函数
bool cmp(int a,int b){
return a>b;//按照自己希望的的方式来定义大小关系
}
栈stack的使用
C++中提供了栈的标准模板库,在使用栈时需要在头文件中加入:include
- stack 可以看作一种新的容器类型,但是它的特殊之处就在于栈的存取操作是先进后出。
- 入栈操作:s.push() 将括号里面的内容压入栈内
- 打印,取出,获得栈顶元素: s.top()
- 出栈操作:s.pop() 将栈里面的元素出栈
- 判断栈是否为空栈:s.empty()
上面描述的一些操作如下
1 | //栈的实现 |
C++中队列的使用
队列也是C++中的一种标准容器类,其最大的特点就是先进先出。在头文件中要加入 #include
- push() 向队列中插入新的元素,由于队列是基于先进先出,在执行push()操作时,新插入的元素放在队尾
- pop() 将位于队列中最靠前的值拿掉
- size() 返回队列的长度,队列中元素的个数
- empty() 判断队列是否为一个空队列,若是队列为空,则返回true
- front() 返回当前队列的第一个元素
使用案例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14//队列的操作
queue<string> my_queue;
my_queue.push("Hello World");
my_queue.push("I love China");
my_queue.push("Nice to meet you");
cout << "队头的元素为:" << my_queue.front() << endl;
cout << "队的长度为" << my_queue.size() << endl;
int i = 1;
while (!my_queue.empty())
{
cout << "队中第" << i << "个元素为:" << my_queue.front() << endl << endl;
i++;
my_queue.pop();
}
利用数组创建一个链式结构
有时候我们已经获得链表中的数据元素项目,将链表中的元素已经顺序存入了一个vector中,现在需要将vector中的元素构造出一个链表,可以通过下面描述的方法进行操作:
- 首先我们新建一个节点,并将节点指向为NULL listNOde *head=nullptr;
- 对容器进行遍历,每次遍历时,都新建一个新的节点,并且节点的储值赋值为 当前容器中的元素
- 令当前新建的节点的下一节点指向 head;
- 最后再将当前节点指向head
所以,以上四步操作就实现了不断将新元素放在链表的头部,若是向不改变顺序,应将容器进行逆序遍历,代码如下:1
2
3
4
5
6
7listNode *head=nullptr;
for(int i=nums.size()-1;i>=0;i--)
{
listNode *current=new listNode(nums[i]);
current->next=head;
head=current;
}
指针中函数指针&&指针函数
1.函数指针
说实话,函数指针就是一个特殊的指针,指针都使用来指向一种类型的地址的,函数指针也不例外。函数在执行时,内存会为函数开辟一块专用的内存地址使用,所谓函数指针,就是专门指向函数入口的指针。
其定义同其他类型指针定义有相似之处
1 | /* |
下面附上一段完整的程序代码,定义了一个函数指针(*add),用来指向求和函数addFunc
1 |
|
2.指针函数
指针函数重点强调函数,函数都具有类型,类似于整形函数的返回值类型为整型,指针函数的返回值类型为指针。
下面的范例实现了返回一个类型为指针的指针函数
1 |
|
循环表达式:for(auto c:temp)
此种用法可以不考虑数组的长度来对数组进行遍历,尤其经常使用在map结构中,可以实现map第一个元素的跳动。下面的例程中,map中存放了数组元nums中每个元素出现的次数,我们需要找出元素数目小于2的,可以通过for(auto c:temp)来开启循环语句。
1 | //剑指offer 56题,找出数组中不重复的两个数字 |
二进制位操作
有时候需要对数据进行按位操作,在C++中,可以直接对整形数据进行按位逻辑操作,移位操作
- (&) a&b,a,b均为int类型,表示将整形数字a和b将
C/C++内存四区
- 代码区:存放函数体的二进制代码,由操作系统管理
- 全局区:存放全局变量,静态变量与常量
- 栈区:存放局部变量,函数的形参值,函数的返回值
- 堆区:由程序员手动创建(new malloc等),使用后需要手动释放(free,delete等)。
C++ sort的时间复杂度
C++中sort的时间复杂度为nlogn,有些题目中对时间复杂度有要求,二分查找logn 肯定要好于直接遍历n;
String 中 find()与substr()的用法
C++中find函数用于寻找子字符串,substr()用于分割字符串,find函数返回EOF 表示不是子字符串,是字符串则返回第一次出现时的下标,
C++中substr用于分割,s.substr(star起始位置下表,len往后寻找元素个数),注意第二个元素的意义为向后寻找的元素的个数。
程序实例
1 |
|
二维数组vector定义
1 | vector<vector<int>> dp(rows,vector<int>(coloumns,0)); |
Set类模板的用法
SET()是一种包含已排序对象的关联容器。 set集合容器实现了红黑树(Red-Black Tree)的平衡二叉检索树的数据结构,在插入元素时,它会自动调整二叉树的排列,把元素放到适当的位置,它不会插入相同键值的元素,而采取忽略处理,而且会自动完成排序。
set种常用的操作有:
1 | begin(); // 返回指向第一个元素的迭代器 |
静态成员static
先介绍一下static:在成员变量和成员函数前加static 时,那么该成员变量或成员函数的使用范围就限定在当前程序文件下,不能为外部文件调用(默认不加static 时相当于external属性,可在文件外被调用)
这里给出C语言中static的官方说法:
给C语言初学者:利用static属性隐藏变量和函数名字C程序员使用static属性在模块内部隐藏变量和函数声明,就像你在Java和C++中使用public和private声明一样。C源代码文件扮演模块的角色。任何声明带有static属性的全局变量或者函数都是模块私有的。类似的,任何声明为不带static属性的全局变量和函数都是公共的,可以被其它模块访问。尽可能用static属性来保护你的变量和函数是很好的编程习惯。
- 最后对static的三条作用做一句话总结。首先static的最主要功能是隐藏,其次因为static变量存放在静态存储区,所以它具备持久性和默认值0。
C++类中的静态成员函数和静态成员变量
C++类中用static 修饰成员函数和成员变量,可以总结的规律有:
1、静态成员函数和变量不再专属于每一个对象了,它是属于类的,可以通过对象进行调用,也可以通过类进行调用。
2、静态成员函数只能访问修改静态成员,而不能访问修改非静态成员(因为非静态是属于共有的)
优先级队列 priority_queue
优先级队列需要使用头文件#include
1 | pop():弹出堆顶部元素(大根堆,弹出最大元素) |

